

Artificial intelligence is here. It’s overhyped, poorly understood, and flawed but already core to our lives—and it’s only going to extend its reach. AI powers driverless car research, spots otherwise invisible signs of disease on medical images, finds an answer when you ask Alexa a question, and lets you unlock your phone with your face to talk to friends as an animated poop on the iPhone X using Apple’s Animoji. Those are just a few ways AI already touches our lives, and there’s plenty of work still to be done. But don’t worry, superintelligent algorithms aren’t about to take all the jobs or wipe out humanity. The current boom in all things AI was catalyzed by breakthroughs in an area known as machine learning. It involves “training” computers to perform tasks based on examples, rather than relying on programming by a human. A technique called deep learning has made this approach much more powerful. Just ask Lee Sedol, holder of 18 international titles at the complex game of Go. He got creamed by software called AlphaGo in 2016. There’s evidence that AI can make us happier and healthier. But there’s also reason for caution. Incidents in which algorithms picked up or amplified societal biases around race or gender show that an AI-enhanced future won’t automatically be a better one. Artificial intelligence as we know it began as a vacation project. Dartmouth professor John McCarthy coined the term in the summer of 1956, when he invited a small group to spend a few weeks musing on how to make machines do things like use language. The Dartmouth Summer Research Project on Artificial Intelligence coins the name of a new field concerned with making software smart like humans. Joseph Weizenbaum at MIT creates Eliza, the first chatbot, which poses as a psychotherapist. Meta-Dendral, a program developed at Stanford to interpret chemical analyses, makes the first discoveries by a computer to be published in a refereed journal. A Mercedes van fitted with two cameras and a bunch of computers drives itself 20 kilometers along a German highway at more than 55 mph, in an academic project led by engineer Ernst Dickmanns. IBM’s computer Deep Blue defeats chess world champion Garry Kasparov. The Pentagon stages the Darpa Grand Challenge, a race for robot cars in the Mojave Desert that catalyzes the autonomous-car industry. Researchers in a niche field called deep learning spur new corporate interest in AI by showing their ideas can make speech and image recognition much more accurate. AlphaGo, created by Google unit DeepMind, defeats a world champion player of the board game Go. He had high hopes of a breakthrough in the drive toward human-level machines. “We think that a significant advance can be made,” he wrote with his co-organizers, “if a carefully selected group of scientists work on it together for a summer.” Those hopes were not met, and McCarthy later conceded that he had been overly optimistic. But the workshop helped researchers dreaming of intelligent machines coalesce into a recognized academic field. Early work often focused on solving fairly abstract problems in math and logic. But it wasn’t long before AI started to show promising results on more human tasks. In the late 1950s, Arthur Samuel created programs that learned to play checkers. In 1962, one scored a win over a master at the game. In 1967, a program called Dendral showed it could replicate the way chemists interpreted mass-spectrometry data on the makeup of chemical samples. As the field of AI developed, so did different strategies for making smarter machines. Some researchers tried to distill human knowledge into code or come up with rules for specific tasks, like understanding language. Others were inspired by the importance of learning to understand human and animal intelligence. They built systems that could get better at a task over time, perhaps by simulating evolution or by learning from example data. The field hit milestone after milestone as computers mastered tasks that could previously only be completed by people. Deep learning, the rocket fuel of the current AI boom, is a revival of one of the oldest ideas in AI. The technique involves passing data through webs of math loosely inspired by the working of brain cells that are known as artificial neural networks. As a network processes training data, connections between the parts of the network adjust, building up an ability to interpret future data. Artificial neural networks became an established idea in AI not long after the Dartmouth workshop. The room-filling Perceptron Mark 1 from 1958, for example, learned to distinguish different geometric shapes and got written up in The New York Times as the “Embryo of Computer Designed to Read and Grow Wiser.” But neural networks tumbled from favor after an influential 1969 book coauthored by MIT’s Marvin Minsky suggested they couldn’t be very powerful. Not everyone was convinced by the skeptics, however, and some researchers kept the technique alive over the decades. They were vindicated in 2012, when a series of experiments showed that neural networks fueled with large piles of data could give machines new powers of perception. Churning through so much data was difficult using traditional computer chips, but a shift to graphics cards precipitated an explosion in processing power. In one notable result, researchers at the University of Toronto trounced rivals in an annual competition where software is tasked with categorizing images. In another, researchers from IBM, Microsoft, and Google teamed up to publish results showing deep learning could also deliver a significant jump in the accuracy of speech recognition. Tech companies began frantically hiring all the deep-learning experts they could find. It’s important to note however that the AI field has had several booms and busts (aka, “AI winters”) in the past, and a sea change remains a possibility again today. Improvements to AI hardware, growth in training courses in machine learning, and open source machine-learning projects have accelerated the spread of AI to other industries, from national security to business support and medicine. Alphabet-owned DeepMind has turned its AI loose on a variety of problems: the movement of soccer players, the restoration of ancient texts, and even ways to control nuclear fusion. In 2020, DeepMind said that its AlphaFold AI could predict the structure of proteins, a long-standing problem that had hampered research. This was widely seen as one of the first times a real scientific question has been answered with AI. AlphaFold was subsequently used to study Covid-19 and is now helping scientists study neglected diseases. Meanwhile, consumers can expect to be pitched more gadgets and services with AI-powered features. Google and Amazon, in particular, are betting that improvements in machine learning will make their virtual assistants and smart speakers more powerful. Amazon, for example, has devices with cameras to look at their owners and the world around them. Much progress has been made in the past two decades, but there’s plenty to work on. Despite the flurry of recent progress in AI and wild prognostications about its near future, there are still many things that machines can’t do, such as understanding the nuances of language, commonsense reasoning, and learning new skills from just one or two examples. AI software will need to master tasks like these if it is to get close to the multifaceted, adaptable, and creative intelligence of humans, an idea known as artificial general intelligence that may never be possible. One deep-learning pioneer, Google’s Geoff Hinton, argues that making progress on that grand challenge will require rethinking some of the foundations of the field. There’s a particular type of AI making headlines—in some cases, actually writing them too. Generative AI is a catch-all term for AI that can cobble together bits and pieces from the digital world to make something new—well, new-ish—such as art, illustrations, images, complete and functional code, and tranches of text that pass not only the Turing test, but MBA exams. Tools such as OpenAI’s Chat-GPT text generator and Stable Diffusion’s text-to-image maker manage this by sucking up unbelievable amounts of data, analyzing the patterns using neural networks, and regurgitating it in sensible ways. The natural language system behind Chat-GPT has churned through the entire internet, as well as an untold number of books, letting it answer questions, write content from prompts, and—in the case of CNET—write explanatory articles for websites to match search terms. (To be clear, this article was not written by Chat-GPT, though including text generated by the natural language system is quickly becoming an AI-writing cliche.) While investors are drooling, writers, visual artists, and other creators are naturally worried: Chatbots are (or at least appear to be) cheap, and humans require a livable income. Why pay an illustrator for an image when you can prompt Dall-E to make something for free? Content makers aren’t the only ones concerned. Google is quietly ramping up its AI efforts in response to OpenAI’s accomplishments, and the search giant should be worried about what happens to people’s search habits when chatbots can answer questions for us. So long Googling, hello Chat-GPTing? Challenges loom on the horizon, however. AI models need more and more data to improve, but OpenAI has already used the easy sources; finding new piles of written text to use won’t be easy or free. Legal challenges also loom: OpenAI is training its system on text and images that may be under copyright, perhaps even created by the very same people whose jobs are at risk from this technology. And as more online content is created using AI, it creates a feedback loop in which the online data-training models won’t be created by humans, but by machines. Data aside, there’s a fundamental problem with such language models: They spit out text that reads well enough but is not necessarily accurate. As smart as these models are, they don’t know what they’re saying or have any concept of truth—that’s easily forgotten amid the mad rush to make use of such tools for new businesses or to create content. Words aren’t just supposed to sound good, they’re meant to convey meaning too. There are as many critics of AI as there are cheerleaders—which is good news, given the hype surrounding this set of technologies. Criticism of AI touches on issues as disparate as sustainability, ethics, bias, disinformation, and even copyright, with some arguing the technology is not as capable as most believe and others predicting it’ll be the end of humanity as we know it. It’s a lot to consider. The development of computers capable of tasks that typically require human intelligence. Using example data or experience to refine how computers make predictions or perform a task. A machine learning technique in which data is filtered through self-adjusting networks of math loosely inspired by neurons in the brain. Showing software labeled example data, such as photographs, to teach a computer what to do. Learning without annotated examples, just from experience of data or the world—trivial for humans but not generally practical for machines. Yet. Software that experiments with different actions to figure out how to maximize a virtual reward, such as scoring points in a game. As yet nonexistent software that displays a humanlike ability to adapt to different environments and tasks, and transfer knowledge between them. To start, deep learning inherently requires huge swathes of data, and though innovations in chips mean we can do that faster and more efficiently than ever, there’s no question that AI research churns through energy. A startup estimated that in teaching one system to solve a Rubik’s Cube using a robotic hand OpenAI consumed 2.8 gigawatt-hours of electricity—as much as three nuclear plants could output in an hour. Other estimates suggest training an AI model emits as much carbon dioxide as five American cars being manufactured and driven for their average lifespan. There are techniques to reduce the impact: Researchers are developing more efficient training techniques, models can be chopped up so only necessary sections are run, and data centers and labs are shifting to cleaner energy. AI also has a role to play in improving efficiencies in other industries and otherwise helping address the climate crisis. But boosting the accuracy of AI generally means having more complicated models sift through more data—OpenAI’s GPT2 model reportedly had 1.5 billion weights to assess data, while GPT3 had 175 billion—suggesting AI’s sustainability could get worse before it improves. Vacuuming up all the data needed to build these models creates additional challenges, beyond the shrinking availability of fresh data mentioned above. Bias remains a core problem: Data sets reflect the world around us, and that means models absorb our racism, sexism, and other cultural assumptions. This causes a host of serious problems: AI trained to spot skin cancer performs better on white skin; software designed to predict recidivism inherently rates Black people as more likely to reoffend; and flawed AI facial recognition software has already incorrectly identified Black men, leading to their arrests. And sometimes the AI simply doesn’t work: One violent crime prediction tool for police was wildly inaccurate because of an apparent coding error. Again, mitigations are possible. More inclusive data sets could help tackle bias at the source, while forcing tech companies to explain algorithmic decision-making could add a layer of accountability. Diversifying the industry beyond white men wouldn’t hurt, either. But the most serious challenges may require regulating—and perhaps banning—the use of AI decision-making in situations with the most risk of serious damage to people. Those are a few examples of unwanted outcomes. But people are also already using AI for nefarious ends, such as to create deepfakes and spread disinformation. While AI-edited or AI-generated videos and images have intriguing use cases—such as filling in for voice actors after they leave a show or pass away—generative AI has also been used to make deepfake porn, adding famous faces to adult actors, or used to defame everyday individuals. And AI has been used to flood the web with disinformation, though fact-checkers have turned to the technology to fight back. As AI systems grow more powerful, they will rightly invite more scrutiny. Government use of software in areas such as criminal justice is often flawed or secretive, and corporations like Meta have begun confronting the downsides of their own life-shaping algorithms. More powerful AI has the potential to create worse problems, for example by perpetuating historical biases and stereotypes against women or Black people. Civil-society groups and even the tech industry itself are now exploring rules and guidelines on the safety and ethics of AI. But the hype around generative models suggests we still haven’t learned our lesson when it comes to AI. We need to calm down; understand how it works and when it doesn’t; and then roll out this tool in a careful, considered manner, mitigating concerns as they’re raised. AI has real potential to better—and even extend—our lives, but to truly reap the benefits of machines getting smarter, we’ll need to get smarter about machines. This guide was last updated on February 8, 2023. Enjoyed this deep dive? Check out more WIRED Guides. More From WIRED Reviews and Guides © 2025 Condé Nast. All rights reserved. WIRED may earn a portion of sales from products that are purchased through our site as part of our Affiliate Partnerships with retailers. The material on this site may not be reproduced, distributed, transmitted, cached or otherwise used, except with the prior written permission of Condé Nast. Ad Choices















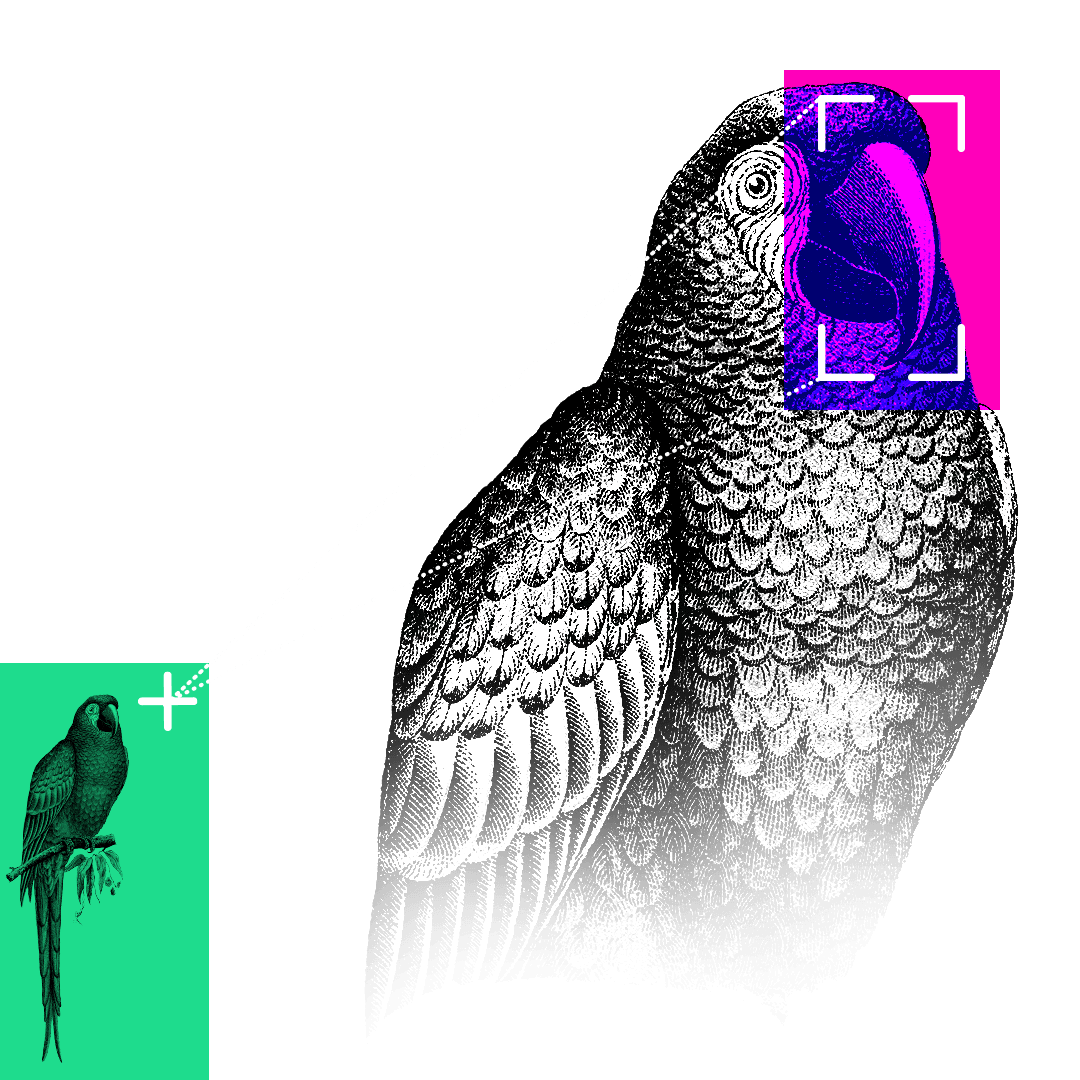
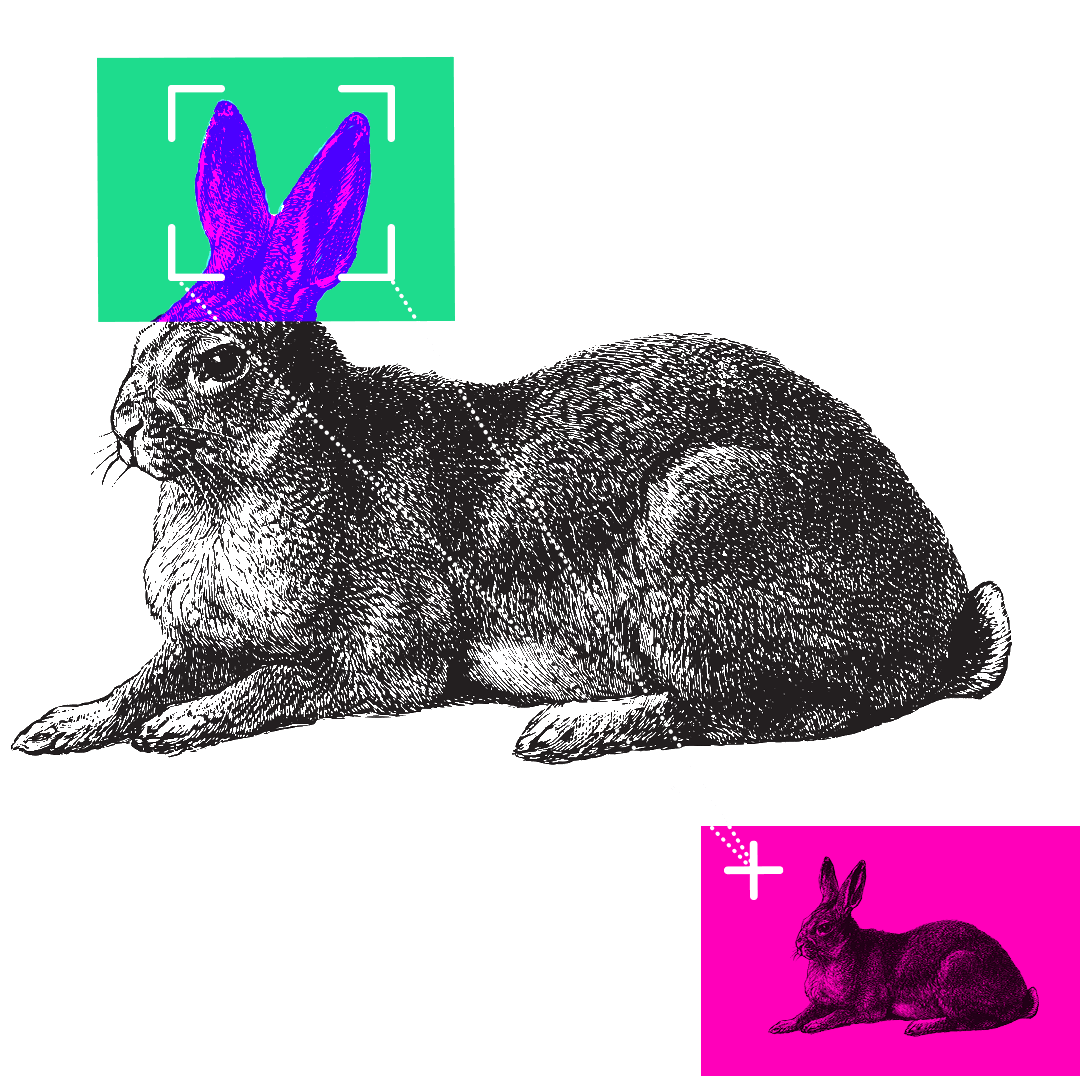
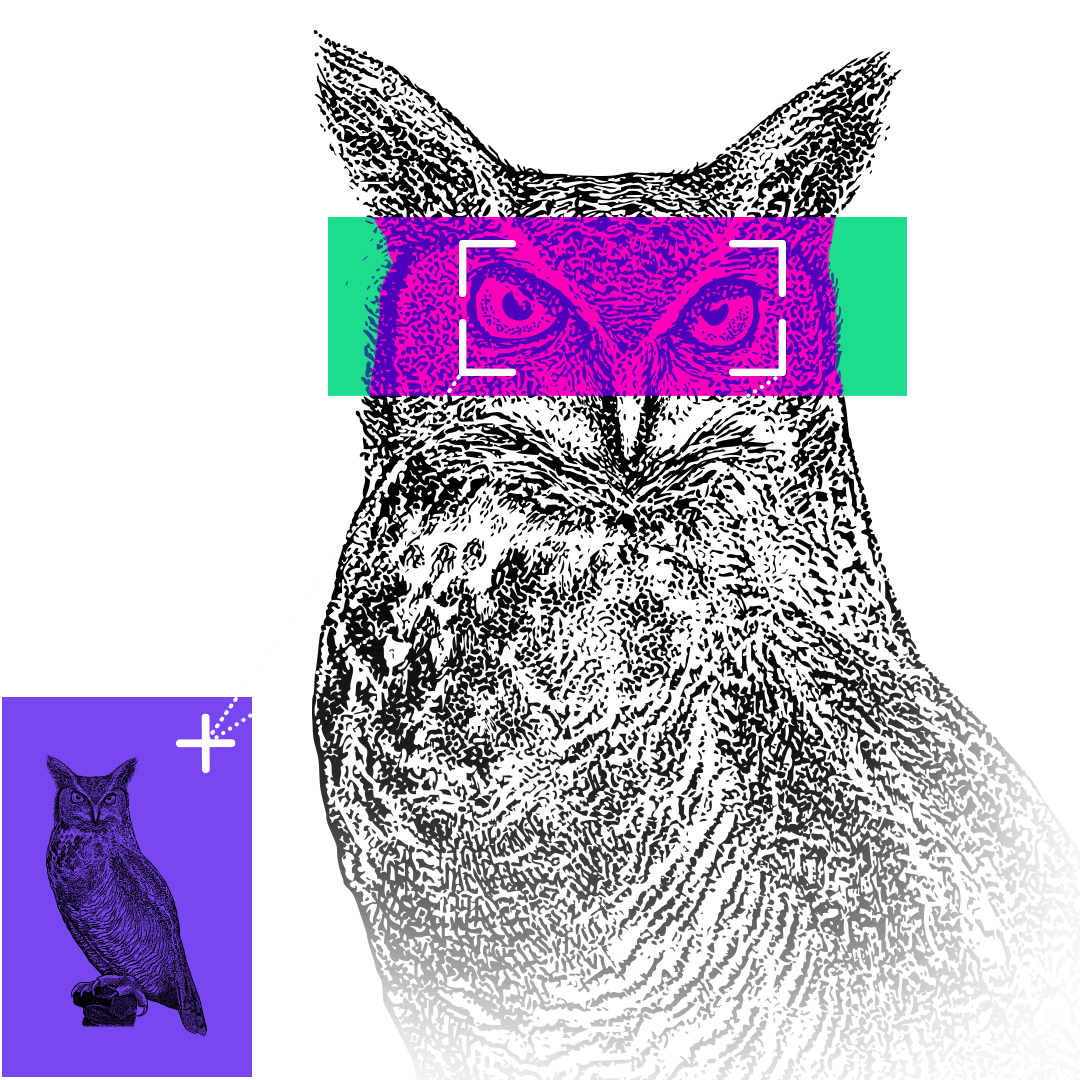
Have you got your head around artificial intelligence yet? In the past six months, chatbots, like ChatGPT, and image generators, such as Midjourney, have rapidly become a cultural phenomenon. But artificial intelligence (AI) or „machine learning” models have been evolving for a while. In this beginner’s guide, we’ll venture beyond chatbots to discover various species of AI – and see how these strange new digital creatures are already playing a part in our lives. The key to all machine learning is a process called training, where a computer program is given a large amount of data – sometimes with labels explaining what the data is – and a set of instructions. The instruction might be something like: „find all the images containing faces” or, „categorise these sounds”. The program will then search for patterns in the data it has been given to achieve these goals. It might need some nudging along the way – such as „that’s not a face” or „those two sounds are different” – but what the program learns from the data and the clues it is given becomes the AI model – and the training material ends up defining its abilities. One way to look at how this training process could create different types of AI is to think about different animals. Over millions of years, the natural environment has led to animals developing specific abilities, in a similar way, the millions of cycles an AI makes through its training data will shape the way it develops and lead to specialist AI models. So what are some examples of how we have trained AIs to develop different skills? Think of a chatbot as a bit like a parrot. It’s a mimic and can repeat words it has heard with some understanding of their context but without a full sense of their meaning. Chatbots do the same – though on a more sophisticated level – and are on the verge of changing our relationship with the written word. But how do these chatbots know how to write? They are a type of AI known as large language models (LLMs) and are trained with huge volumes of text. An LLM is able to consider not just individual words but whole sentences and compare the use of words and phrases in a passage to other examples across all of its training data. Using these billions of comparisons between words and phrases it is able to read a question and generate an answer – like predictive text messaging on your phone but on a massive scale. The amazing thing about large language models is they can learn the rules of grammar and how to use words in the correct context, without human assistance. If you’ve used Alexa, Siri or any other type of voice recognition system, then you’ve been using AI. Imagine a rabbit with its big ears, adapted to capture tiny variations in sound. The AI records the sounds as you speak, removes the background noise, separates your speech into phonetic units – the individual sounds that make up a spoken word – and then matches them to a library of language sounds. Your speech is then turned into text where any listening errors can be corrected before a response is given. This type of artificial intelligence is known as natural language processing. It is the technology behind everything from you saying „yes” to confirm a phone-banking transaction, to asking your mobile phone to tell you about the weather for the next few days in a city you are travelling to. Has your phone ever gathered your photos into folders with names like „at the beach” or „nights out”? Then you’ve been using AI without realising. An AI algorithm uncovered patterns in your photos and grouped them for you. These programs have been trained by looking through a mountain of images, all labelled with a simple description. If you give an image-recognition AI enough images labelled „bicycle”, eventually it will start to work out what a bicycle looks like and how it is different from a boat or a car. Sometimes the AI is trained to uncover tiny differences within similar images. This is how facial recognition works, finding a subtle relationship between features on your face that make it distinct and unique when compared to every other face on the planet. The same kind of algorithms have been trained with medical scans to identify life-threatening tumours and can work through thousands of scans in the time it would take a consultant to make a decision on just one. Recently image recognition has been adapted into AI models which have learned the chameleon-like power of manipulating patterns and colours. These image-generating AIs can turn the complex visual patterns they gather from millions of photographs and drawings into completely new images. You can ask the AI to create a photographic image of something that never happened – for example, a photo of a person walking on the surface of Mars. Or you can creatively direct the style of an image: „Make a portrait of the England football manager, painted in the style of Picasso.” The latest AIs start the process of generating this new image with a collection of randomly coloured pixels. It looks at the random dots for any hint of a pattern it learned during training – patterns for building different objects. These patterns are slowly enhanced by adding further layers of random dots, keeping dots which develop the pattern and discarding others, until finally a likeness emerges. Develop all the necessary patterns like „Mars surface”, „astronaut” and „walking” together and you have a new image. Because the new image is built from layers of random pixels, the result is something which has never existed before but is still based on the billions of patterns it learned from the original training images. Society is now beginning to grapple with what this means for things like copyright and the ethics of creating artworks trained on the hard work of real artists, designers and photographers. Self-driving cars have been part of the conversation around AI for decades and science fiction has fixed them in the popular imagination. Self-driving AI is known as autonomous driving and the cars are fitted with cameras, radar and range-sensing lasers. Think of a dragonfly, with 360-degree vision and sensors on its wings to help it manoeuvre and make constant in-flight adjustments. In a similar way, the AI model uses the data from its sensors to identify objects and figure out whether they are moving and, if so, what kind of moving object they are – another car, a bicycle, a pedestrian or something else. Thousands and thousands of hours of training to understand what good driving looks like has enabled AI to be able to make decisions and take action in the real world to drive the car and avoid collisions. Predictive algorithms may have struggled for many years to deal with the often unpredictable nature of human drivers, but driverless cars have now collected millions of miles of data on real roads. In San Francisco, they are already carrying paying passengers. Autonomous driving is also a very public example of how new technologies must overcome more than just technical hurdles. Government legislation and safety regulations, along with a deep sense of anxiety over what happens when we hand over control to machines, are all still potential roadblocks for a fully automated future on our roads. Some AIs simply deal with numbers, collecting and combining them in volume to create a swarm of information, the products of which can be extremely valuable. There are likely already several profiles of your financial and social actions, particularly those online, which could be used to make predictions about your behaviour. Your supermarket loyalty card is tracking your habits and tastes through your weekly shop. The credit agencies track how much you have in the bank and owe on your credit cards. Netflix and Amazon are keeping track of how many hours of content you streamed last night. Your social media accounts know how many videos you commented on today. And it’s not just you, these numbers exist for everyone, enabling AI models to churn through them looking for social trends. These AI models are already shaping your life, from helping decide if you can get a loan or mortgage, to influencing what you buy by choosing which ads you see online. Would it be possible to combine some of these skills into a single, hybrid AI model? That is exactly what one of the most recent advances in AI does. It’s called multimodal AI and allows a model to look at different types of data – such as images, text, audio or video – and uncover new patterns between them. This multimodal approach was one of the reasons for the huge leap in ability shown by ChatGPT when its AI model was updated from GPT3.5, which was trained only on text, to GPT4, which was trained with images as well. The idea of a single AI model able to process any kind of data and therefore perform any task, from translating between languages to designing new drugs, is known as artificial general intelligence (AGI). For some it’s the ultimate aim of all artificial intelligence research; for others it’s a pathway to all those science fiction dystopias in which we unleash an intelligence so far beyond our understanding that we are no longer able to control it. Until recently the key process in training most AIs was known as „supervised learning”. Huge sets of training data were given labels by humans and the AI was asked to figure out patterns in the data. The AI was then asked to apply these patterns to some new data and give feedback on its accuracy. For example, imagine giving an AI a dozen photos – six are labelled „car” and six are labelled „van”. Next tell the AI to work out a visual pattern that sorts the cars and the vans into two groups. Now what do you think happens when you ask it to categorise this photo? Unfortunately, it seems the AI thinks this is a van – not so intelligent. Now you show it this. And it tells you this is a car. It’s pretty clear what’s gone wrong. From the limited number of images it was trained with, the AI has decided colour is the strongest way to separate cars and vans. But the amazing thing about the AI program is that it came to this decision on its own – and we can help it refine its decision-making. We can tell it that it has wrongly identified the two new objects – this will force it to find a new pattern in the images. But more importantly, we can correct the bias in our training data by giving it more varied images. These two simple actions taken together – and on a vast scale – are how most AI systems have been trained to make incredibly complex decisions. Supervised learning is an incredibly powerful training method, but many recent breakthroughs in AI have been made possible by unsupervised learning. In the simplest terms, this is where the use of complex algorithms and huge datasets means the AI can learn without any human guidance. ChatGPT might be the most well-known example. The amount of text on the internet and in digitised books is so vast that over many months ChatGPT was able to learn how to combine words in a meaningful way by itself, with humans then helping to fine-tune its responses. Imagine you had a big pile of books in a foreign language, maybe some of them with images. Eventually you might work out that the same word appeared on a page whenever there was drawing or photo of a tree, and another word when there was a photo of a house. And you would see that there was often a word near those words that might mean “a” or maybe “the” – and so on. ChatGPT made this kind of close analysis of the relationship between words to build a huge statistical model which it can then use to make predictions and generate new sentences. It relies on enormous amounts of computing power which allows the AI to memorise vast amounts of words – alone, in groups, in sentences and across pages – and then read and compare how they are used over and over and over again in a fraction of a second. The rapid advances made by deep learning models in the last year have driven a wave of enthusiasm and also led to more public engagement with concerns over the future of artificial intelligence. There has been much discussion about the way biases in training data collected from the internet – such as racist, sexist and violent speech or narrow cultural perspectives – leads to artificial intelligence replicating human prejudices. Another worry is that artificial intelligence could be tasked to solve problems without fully considering the ethics or wider implications of its actions, creating new problems in the process. Within AI circles this has become known as the „paperclip maximiser problem”, after a thought experiment by the philosopher Nick Bostrom. He imagined an artificial intelligence asked to create as many paperclips as possible which slowly diverts every natural resource on the planet to fulfil its mission – including killing humans to use as raw materials for more paperclips. Others say that, rather than focusing on murderous AIs of the future, we should be more concerned with the immediate problem of how people could use existing AI tools to increase distrust in politics and scepticism of all forms of media. In particular, the world’s eyes are on the 2024 presidential election in the US, to see how voters and political parties cope with a new level of sophisticated disinformation. What happens if social media is flooded with fake videos of presidential candidates, created with AI and each tailored to anger a different group of voters? In Europe, the EU is creating an Artificial Intelligence Act to protect its citizens’ rights by regulating the deployment of AI – for instance, a ban on using facial recognition to track or identify people in real-time in public spaces. These are among the first laws in the world to establish guidelines for the future use of these technologies – setting boundaries on what companies and governments will and will not be allowed to do – but, as the capabilities of artificial intelligence continue to grow, they are unlikely to be the last. Written by Paul Sargeant Design by Jenny Law, Debie Loizou, Patricia Ofuono and Oli Powell Development by Assiz Pereira and Alli Shultes. Testing by Jerina Jacob Production management by Holly Frampton. Additional editing by Emma Atkinson and Bella Hurrell. With thanks to Maryam Ahmed for her guidance on machine learning models. Photos: Getty Images




















Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript. Advertisement You can also search for this author in PubMed Google Scholar Credit: Lionel Bonaventure/AFP via Getty A new and seemingly more impressive artificial intelligence (AI) tool is released almost weekly, and researchers are flocking to try them out. Whether they are looking to edit manuscripts, write code or generate hypotheses, researchers have more generative AI tools to choose from than ever before. Each large language model (LLM) is suited to different tasks. Some are available through free chatbots, whereas others use a paid-for application programming interface (API) that means they can be integrated with other software. A few can also be downloaded, allowing researchers to build their own custom models. Although LLMs produce human-like responses, they all remain too error-prone to be used on their own, says Carrie Wright, a data scientist at the Fred Hutchinson Cancer Center, headquartered in Seattle, Washington. So which LLM is best for what task? Here, researchers share their current favourites with Nature to help guide those in need. OpenAI, based in San Francisco, California, introduced the world to LLMs in 2022 with its free-to-use ChatGPT bot. Scientists have mainly used the bot to look up information or as a writing assistant, for example to draft abstracts, but newer models are broadening the technology’s potential uses. Last September, in the firm’s most significant advance since then, OpenAI wowed scientists with its o1 ‘reasoning model’, which it followed with the more advanced o3 in December. Both reasoning models work more slowly than an LLM alone does, because they have been trained to answer queries in a step-by-step way. This ‘chain of thought’ process, aimed at simulating human reasoning, has helped them to smash tough benchmarks in science and mathematics. It has also made them good at technical tasks, such as solving coding issues and reformatting data. After the little-known Chinese start-up DeepSeek in Hangzhou launched a rival reasoner on 20 January, OpenAI responded with a range of new tools. These include a speedy o3-mini — a reasoner that is free for registered chatbot users — and ‘deep research’, which allows some paying subscribers to create reports that synthesize information, with citations, from hundreds of websites, akin to carrying out a literature review. The models excel when used in combination, says Andrew White, a chemist and AI expert at FutureHouse, a start-up in San Francisco. When it comes to tasks such as picking apart unfamiliar concepts in a new mathematical proof, o3-mini does a “really good job”, says Simon Frieder, a mathematician and AI researcher at the University of Oxford, UK. But even the best models “are still not even close to rivalling a mathematician”, he says. DeepSeek-R1, launched last month, has abilities on a par with o1’s, but is available through an API at a fraction of the cost. It also stands apart from OpenAI’s models because it is open weight, meaning that although its training data have not been released, anyone can download the underlying model and tailor it to their specific research project. R1 has “just unlocked a new paradigm” in which communities, particularly those with relatively few resources, can build specialized reasoning models, says White. Running the full model requires access to powerful computing chips, which many academics lack. But researchers such as Benyou Wang, a computer scientist at the Chinese University of Hong Kong, Shenzhen, are creating versions that can run or train on a single machine. Like o1, DeepSeek-R1’s forte is maths problems and writing code. But it is also good at tasks such as generating hypotheses, says White. This is because DeepSeek has opted to publish the model’s ‘thought processes’ in full, which allows researchers to better refine their follow-up questions and ultimately improve its outputs, he says. Such transparency could also be hugely powerful for medical diagnostics. Wang is adapting R1 in experiments that use the model’s reasoning-like powers to build “a clear and logical pathway from patient assessment to diagnosis and treatment recommendation”, he says. DeepSeek-R1 has some cons. The model seems to have a particularly long ‘thought’ process, which slows it down and makes it less useful for looking up information or brainstorming. Concerns about the security of data input into its API and chatbot have led several governments to ban workers at national agencies from using the chatbot. DeepSeek also seems to have taken fewer measures to mitigate its models generating harmful outputs than have its commercial competitors. Adding filters to prevent such outputs — instructions to make weapons, for instance — takes time and effort. Although it is unlikely that this was done on purpose, “the lack of guard rails is worrisome”, says Simon. OpenAI has also suggested that DeepSeek may have “inappropriately distilled” its models, referring to a method for training a model on another algorithm’s outputs, which OpenAI’s conditions of use prohibit. DeepSeek could not be reached for comment on these criticisms before this article was published. Some researchers see such distillation as commonplace and are happy to use R1, but others are wary of using a tool that could be subject to future litigation. There’s a chance that scientists using R1 could be forced to retract papers, if using the model was considered a violation of the journal’s ethical standards, says Ana Catarina De Alencar, a lawyer at EIT Manufacturing in Paris who specializes in AI law. A similar situation could apply to the use of models by OpenAI and other firms accused of intellectual-property violations, says De Alencar. News organizations claim that the firms used journalistic content to train their models without permission. Llama has long been a go-to LLM for the research community. A family of open-weight models first released by Meta AI in Menlo Park, California, in 2023, versions of Llama have been downloaded more than 600 million times through the open-science platform Hugging Face alone. The fact it can be downloaded and built on is “probably why Llama has been embraced by the research community”, says Elizabeth Humphries, a data scientist at the Fred Hutchinson Cancer Center. Being able to run an LLM on personal or institutional servers is essential when working with proprietary or protected data, to avoid sensitive information being fed back to other users or to the developers, says Wright. Researchers have built on Llama’s models to make LLMs that predict materials’ crystal structure, as well as to simulate the outputs of a quantum computer. Tianlong Chen, a machine-learning scientist at the University of North Carolina at Chapel Hill, says Llama was a good fit for simulating a quantum computer because it was relatively easy to adapt it to understand specialized quantum language. But Llama requires users to request permission to access it, which is minor point of friction for some, says White. As a result, other open models such as OLMo, developed by the Allen Institute for Artificial Intelligence in Seattle, or Qwen, built by the Chinese firm Alibaba Cloud, based in Hangzhou, are now often the first choice in research, he adds. DeepSeek’s efficient underlying V3 model is also a rival base for building scientific models. or doi: https://doi.org/10.1038/d41586-025-00437-0 Reprints and permissions How China created AI model DeepSeek and shocked the world Scientists flock to DeepSeek: how they’re using the blockbuster AI model China’s cheap, open AI model DeepSeek thrills scientists How should we test AI for human-level intelligence? OpenAI’s o3 electrifies quest Researchers built an ‘AI Scientist’ — what can it do? Bigger AI chatbots more inclined to spew nonsense — and people don’t always realize Can AI review the scientific literature — and figure out what it all means? How AI is reshaping science and society How AI-powered science search engines can speed up your research A giant leap for machine translation could be even bigger Correspondence 18 FEB 25 Scientists use AI to design life-like enzymes from scratch News 13 FEB 25 Why is mathematics education failing some of the world’s most talented children? Editorial 12 FEB 25 Mapping cells through time and space with moscot Article 22 JAN 25 Accurate predictions on small data with a tabular foundation model Article 08 JAN 25 Why ‘open’ AI systems are actually closed, and why this matters Perspective 27 NOV 24 A human gene makes mice squeak differently — did it contribute to language? News 18 FEB 25 Scientists fight Norway’s language law, warning of talent exodus Career News 11 FEB 25 Breaking language barriers: ‘Not being fluent in English is often viewed as being an inferior scientist’ Career Q&A 10 FEB 25 The Institute of Medical Bioinformatics and Systems Medicine University Medical Center Freiburg is looking for PhD researcher Medical bioinformatics Freiburg im Breisgau, Baden-Württemberg (DE) Miriam von Scheibner Join a cutting-edge research team in brain-computer interaction and neuromodulation for clinical applications. Shanghai, China Fudan University Full-time Faculty Positions in the Molecular Biology and Genetics Department, Koç University Istanbul (TR) Koç University The Department of Materials (www.mat.ethz.ch) at ETH Zurich invites applications for the above-mentioned position. Zurich, Switzerland ETH Zurich Material Mavens Recruitment at Suzhou Lab. Research Director (Chief Scientists), Researcher (Outstanding Scientists), Associate Researcher… Suzhou, Jiangsu, China Suzhou Laboratory How China created AI model DeepSeek and shocked the world Scientists flock to DeepSeek: how they’re using the blockbuster AI model China’s cheap, open AI model DeepSeek thrills scientists How should we test AI for human-level intelligence? OpenAI’s o3 electrifies quest Researchers built an ‘AI Scientist’ — what can it do? Bigger AI chatbots more inclined to spew nonsense — and people don’t always realize Can AI review the scientific literature — and figure out what it all means? How AI is reshaping science and society How AI-powered science search engines can speed up your research An essential round-up of science news, opinion and analysis, delivered to your inbox every weekday. Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily. Nature (Nature) ISSN 1476-4687 (online) ISSN 0028-0836 (print) © 2025 Springer Nature Limited


















Stanford University explore 2023 technology focus areas Artificial Intelligence Artificial Intelligence Biotechnology and Synthetic Biology Biotechnology and Synthetic Biology Cryptography Cryptography Lasers Materials Science Materials Science Neuroscience • Artificial intelligence (AI) is a foundational technology that is supercharging other scientific fields and, like electricity and the internet, has the potential to transform societies, economies, and politics worldwide. • Despite rapid progress in the past several years, even the most advanced AI still has many failure modes that are unpredictable, not widely appreciated, not easily fixed, not explainable, and capable of leading to unintended consequences. • Mandatory governance regimes for AI, even those to stave off catastrophic risks, will face stiff opposition from AI researchers and companies, but voluntary regimes calling for self-governance are more likely to gain support. Artificial intelligence (AI) is the ability of computers to perform functions associated with the human brain, including perceiving, reasoning, learning, interacting, problem solving, and exercising creativity. AI promises to be a fundamental enabler of technological advancement and progress in many fields, arguably as important as electricity or the internet. In 2024, the Nobel Prizes for Physics and Chemistry were awarded for work intimately related to AI. Three of the most important subfields of AI are computer vision, machine learning, and natural language processing. The boundaries between them are often fluid. Computer vision (CV) enables machines to recognize and understand visual information, convert pictures and videos into data, and make decisions based on the results. Machine learning (ML) enables computers to perform tasks without explicit instructions, often by generalizing from patterns in data. ML includes deep learning that relies on multilayered artificial neural networks to model and understand complex relationships within data. Natural language processing (NLP) equips machines with capabilities to understand, interpret, and produce spoken words and written texts. Although AI draws on other subfi elds, it is mostly based on machine learning (ML), which requires data and computing power, often on an enormous scale. Data can take various forms, including text, images, videos, sensor readings, and more. The quality and quantity of data play a crucial role in determining the performance and capabilities of AI models. Models may generate inaccurate or biased outcomes, especially in the absence of suffi cient high-quality data. Furthermore, the hardware costs of training leading AI models are substantial. Currently, only a select number of large US companies have the resources to build cutting-edge models from scratch. Dominating the AI conversation in 2024 were foundation models, which are large-scale systems trained on very large volumes of diverse data. Such training endows them with broad capabilities, and they can apply knowledge learned in one context to a different context, making them more flexible and efficient than traditional task-specific models. Large language models (LLMs) are the most familiar type of foundation model and are trained on very large amounts of text. LLMs are an example of generative AI, which can produce new material based on its training and the inputs it is given using statistical prediction about what other words are likely to be found immediately after the occurrence of certain words. These models generate linguistic output surprisingly similar to that of humans across a wide range of subjects, including computer code, poetry, legal case summaries, and medical advice. Specialized foundation models have also been developed in other modalities such as audio, video, and images. AI users will not be limited to those with specialized training; instead, the average person will interact directly with sophisticated AI applications for a multitude of everyday activities. While AI can automate a wide range of tasks, it promises to enable people to do what they are best at doing. AI systems can work alongside humans, complementing and assisting them. Key sectors poised to take advantage of the technology include healthcare, agriculture, law, and logistics and transportation. One challenge of implementing AI is managing the risks associated with the technology. Some of the known issues with leading AI models include: Explainability Today’s AI is for the most part incapable of explaining how it arrives at a specific conclusion. Explanations are not always necessary, but in cases such as medical decision-making, they may be critical. Bias and fairness Machine learning models are trained on existing datasets, which means that any bias in the data can skew results. Vulnerability to spoofing For many AI models, data inputs can be tweaked to fool them into drawing false conclusions. Deepfakes AI provides the capability for generating highly realistic but entirely inauthentic audio and video, with concerning implications for courtroom evidence and political deception. Overtrust As trust in AI grows, the risk of overlooking errors, mishaps, and unforeseen incidents also increases. Hallucinations AI models can generate results or answers that seem plausible but are completely made up, incorrect, or both. A second challenge is the future of work in an AI-enabled context. AI models have already demonstrated how they can be used in a wide variety of fields, including law, customer support, coding, and journalism, leading to concerns that the impact of AI on employment will be substantial, especially on jobs that involve knowledge work. In some cases, the technology will help workers to increase their productivity and job satisfaction. In others, AI will lead to job losses—and it is not yet clear what new jobs will arise to take their place. Research on foundational AI technologies is difficult to regulate, even among likeminded nations. It is even more difficult, and may well be impossible, to reach agreement between nations that regard each other as strategic competitors and adversaries. The same logic applies to voluntary restrictions on research by companies that compete with each other. Regulation of specific applications of AI may be more easily implemented, in part because of existing regulatory frameworks in domains such as healthcare, finance, and law. Over the past couple of years, nations have explored possible governance regimes. In the United States, the president’s Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence was issued on October 30, 2023. In November 2023 and May 2024, the European Union and twenty-eight nations collectively endorsed international cooperation to manage risks associated with highly capable general-purpose AI models. The European Union’s AI Act entered into force in August 2024. SETR 2025: Artificial Intel… by Hoover Institution Fei-Fei Li is the Sequoia Professor of Computer Science and professor, by courtesy, of psychology at Stanford University. She serves as codirector of Stanford’s Human-Centered AI Institute and as an affiliated faculty at Stanford Bio-X. Her current research includes cognitively inspired AI, machine learning, computer vision, and ambient intelligent systems for health-care delivery. She received her PhD in electrical engineering from the California Institute of Technology. Fei-Fei Li is the Sequoia Professor of Computer Science and professor, by courtesy, of psychology at Stanford University. She serves as codirector of Stanford’s Human-Centered AI Institute and as an affiliated faculty at Stanford Bio-X. Her current research includes cognitively inspired AI, machine learning, computer vision, and ambient intelligent systems for health-care delivery. She received her PhD in electrical engineering from the California Institute of Technology. Read the complete report. Select Content Type Select Author Artificial Intelligence Frontier technologies are transforming international relations and the U.S. economy. As a result, more bridges between science and engineering labs, Washington, DC, and the world of business are needed. The Hoover Institution and Stanford University’s School… The Hoover Institution and the School of Engineering at Stanford University invite you to a panel discussion for the launch of the Stanford Emerging Technology Review 2025 report in Washington, DC. Hoover Institution fellow Drew Endy testifies before the US-China Economic and Security Review Commission at a hearing on „Made in China 2025—Who Is Winning?” Drew Endy, a Hoover science fellow and senior fellow and Martin Family University Fellow in Undergraduate Education (Bioengineering) at Stanford University, convened nearly two dozen Hoover and Stanford experts, policymakers, and business leaders earlier this… Fifty US government officials, scholars from the Hoover Institution, Stanford University scientists and engineers, technology experts, venture capitalists, and business leaders convened at the Sixth Annual Tech Track II Symposium hosted by the Hoover… This chapter explores applications from each of the ten technology fields described in the report as they may relate to five important policy themes: economic growth, national security, environmental and energy sustainability, health and medicine, and civil… One of the most important and unusual hallmarks of this moment is convergence: emerging technologies are intersecting and interacting in a host of ways, with important implications for policy. This chapter identifies themes and commonalities that cut across… This report offers an easy-to-use reference tool that harnesses the expertise of Stanford University’s leading science and engineering faculty in ten major technological areas: artificial intelligence, biotechnology and synthetic biology, cryptography, lasers… Emerging technologies are transforming societies, economies, and geopolitics. Never have we experienced the convergence of so many technologies with the potential to change so much, so fast, and at such high stakes. This report is intended to help readers… The interview also delves into the technological and political evolution of Silicon Valley and Andreessen’s own shifting political affiliations from left to right, along with his vision for leveraging technology to drive societal progress, the role of… © Stanford University. Stanford, California 94305












































{kind=link}
{kind=link}
{kind=link}